![]() v1.3-SNAPSHOT
v1.3-SNAPSHOT
Wikipediaの編集ストリームの監視
このガイドで、スクラッチから始め、FlinkプログラムのセットアップからFlinkクラスタ上のストリーム解析プログラムの実行まで進めるつもりです。
Wikipedia はwikiへの全ての編集が記録されたIRCチャンネルを提供します。このチャンネルをFlink内に読み込み、各ユーザが指定された時間のウィンドウ内で編集したバイト数をカウントするつもりです。Flinkを使って2,3分で実装するのは簡単ですが、自身でもっと複雑な解析プログラムのビルドを開始するのに良い土台になるでしょう。
Mavenプロジェクトのセットアップ
プロジェクトの構造を作成するためにFlink Maven 原型を使うつもりです。これについての詳細はJava API クイックスタートを見てください。目的のために、このコマンドを実行します:
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeCatalog=https://repository.apache.org/content/repositories/snapshots/ \
-DarchetypeVersion=1.3-SNAPSHOT \
-DgroupId=wiki-edits \
-DartifactId=wiki-edits \
-Dversion=0.1 \
-Dpackage=wikiedits \
-DinteractiveMode=false好きなように groupId, artifactId および package を編集することができます。上のパラメータを使って、Mavenは以下のようなプロジェクト構造を生成するでしょう:
$ tree wiki-edits
wiki-edits/
├── pom.xml
└── src
└── main
├── java
│ └── wikiedits
│ ├── BatchJob.java
│ ├── SocketTextStreamWordCount.java
│ ├── StreamingJob.java
│ └── WordCount.java
└── resources
└── log4j.propertiesすでにFlink依存がルートディレクトリに追加されたpom.xml ファイルと、src/main/javaにいくつかのFlinkプログラムの例があります。スクラッチから始めるつもりのため、プログラムの例を削除することができます:
$ rm wiki-edits/src/main/java/wikiedits/*.java最後のステップとしてプログラム内で使えるように依存としてFlink Wikipedia コネクタを追加する必要があります。以下のようにpom.xmlのdependenciesセクションを編集します:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-wikiedits_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>flink-connector-wikiedits_2.11 依存が追加されたことに注意してください。(この例とWikipedia コネクタはHello Samza のApache Samza の例に着想を得ました。)
Flinkプログラムを書く
コーディングの時間です。Fire up your favorite IDE and import the Maven project or open a text editor and create the file src/main/java/wikiedits/WikipediaAnalysis.java:
package wikiedits;
public class WikipediaAnalysis {
public static void main(String[] args) throws Exception {
}
}プログラムは今のところとても基本的なものですが、進むにつれて詰め込んでいくつもりです。IDEがimport文を自動的に追加するため、個々では指定していないことに注意してください。先をスキップしてエディタに入力したい場合は、この章の最後でimport文を含む完全なコードを示すつもりです。
Flinkプログラム内での最初のステップはStreamExecutionEnvironment (バッチジョブを書いている場合は ExecutionEnvironment) を作成することです。これは実行パラメータを設定し外部システムから読み込むためのソースを作成するために使うことができます。では、先に進み、これをmainメソッドに追加しましょう:
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();次に、Wikipedia IRCのログから読み込むソースを生成しましょう:
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());これは先で処理することができるWikipediaEditEvent要素のDataStreamを生成します。この例の目的としては、ユーザが特定の時間ウィンドウ、例えば5秒、で各ユーザが行った追加あるいは削除のバイト数を決定することに興味があります。このために、まずユーザ名でストリームをキー付けしたいことを指定する必要があります。つまり、このストリーム上の操作はアカウント内のユーザ名を取る必要があります。この場合、ウィンドウ内の編集されたバイトの要約はユニークなユーザ毎になければなりません。ストリームをキー付けするために、以下のようにKeySelectorを提供する必要があります:
KeyedStream<WikipediaEditEvent, String> keyedEdits = edits
.keyBy(new KeySelector<WikipediaEditEvent, String>() {
@Override
public String getKey(WikipediaEditEvent event) {
return event.getUser();
}
});これによりStringキー、ユーザ名を持つWikipediaEditEvent のストリームを取得することができます。We can now specify that we want to have windows imposed on this stream and compute a result based on elements in these windows. ウィンドウは計算を実施するストリームの断片を指定します。要素の無限のストリーム上で集約を計算する時にウィンドウが必要です。例では、各5秒間で編集されたバイトの総数を集約したいと言えるでしょう。
DataStream<Tuple2<String, Long>> result = keyedEdits
.timeWindow(Time.seconds(5))
.fold(new Tuple2<>("", 0L), new FoldFunction<WikipediaEditEvent, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> fold(Tuple2<String, Long> acc, WikipediaEditEvent event) {
acc.f0 = event.getUser();
acc.f1 += event.getByteDiff();
return acc;
}
});最初の呼び出し、.timeWindow()、は5秒のウィンドウを(重ねること無しに)ドミノ倒しにしたいことを指定します。2つ目の呼び出しは各ユニークなキーについて各ウィンドウ上での 折り畳み変換を指定します。この場合、("", 0L)の初期値から始め、ユーザについての時間ウィンドウ内の各編集のバイト差分を追加します。これで結果のストリームは5秒毎に発行された各ユーザについてのTuple2<String, Long>を含みます。
残っているのはストリームをコンソールに出力し実行を開始することだけです:
result.print();
see.execute();最後の呼び出しは実際のFlinkのジョブを開始するために必要です。All operations, such as creating sources, transformations and sinks only build up a graph of internal operations. execute() が呼ばれた時のみ、この操作のグラフがクラスタに投げられるか、ローカルマシーン上で実行されます。
これまでの完全なコードはこのようになります:
package wikiedits;
import org.apache.flink.api.common.functions.FoldFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;
public class WikipediaAnalysis {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
KeyedStream<WikipediaEditEvent, String> keyedEdits = edits
.keyBy(new KeySelector<WikipediaEditEvent, String>() {
@Override
public String getKey(WikipediaEditEvent event) {
return event.getUser();
}
});
DataStream<Tuple2<String, Long>> result = keyedEdits
.timeWindow(Time.seconds(5))
.fold(new Tuple2<>("", 0L), new FoldFunction<WikipediaEditEvent, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> fold(Tuple2<String, Long> acc, WikipediaEditEvent event) {
acc.f0 = event.getUser();
acc.f1 += event.getByteDiff();
return acc;
}
});
result.print();
see.execute();
}
}Mavenを使って、IDE内、あるいはコマンドライン上で、この例を実行することができます:
$ mvn clean package
$ mvn exec:java -Dexec.mainClass=wikiedits.WikipediaAnalysis最初のコマンドはプロジェクトをビルドし、2つ目のコマンドはmainクラスを実行します。出力は以下に似たものに違いありません:
1> (Fenix down,114)
6> (AnomieBOT,155)
8> (BD2412bot,-3690)
7> (IgnorantArmies,49)
3> (Ckh3111,69)
5> (Slade360,0)
7> (Narutolovehinata5,2195)
6> (Vuyisa2001,79)
4> (Ms Sarah Welch,269)
4> (KasparBot,-245)各行の先頭の数字は、出力が生成されたprintシンクのどの並行インスタンスかを伝えます。
This should get you started with writing your own Flink programs. もっと学ぶには、基本的な概念 とDataStream APIについてのガイドを調べることができます。自身のマシーン上でFlinkクラスタをセットアップおよび結果のKafkaへの書き込みについてもっと知りたい場合は、特別な課題のために留まってください。
ボーナス練習: クラスタ上で実行しKafkaに書き込む
あなたのマシーン上にFlinkの配布物をセットアップするためにセットアップのクイックスタート に従い、進める前にKafkaインストレーションをセットアップするためにKafka のクイックスタートを参照してください。
最初のステップとして、Kafka シンクを使えるようにするために、Flink Kafkaコネクタを依存物として追加する必要があります。これを依存のセクションのpom.xml ファイルに追加します:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.8_2.11</artifactId>
<version>${flink.version}</version>
</dependency>次に、プログラムを修正する必要があります。print() シンクを削除し、代わりにKafkaシンクを使うでしょう。新しいコードはこのようになります:
result
.map(new MapFunction<Tuple2<String,Long>, String>() {
@Override
public String map(Tuple2<String, Long> tuple) {
return tuple.toString();
}
})
.addSink(new FlinkKafkaProducer08<>("localhost:9092", "wiki-result", new SimpleStringSchema()));関係するクラスもimportされる必要があります:
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer08;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.api.common.functions.MapFunction;MapFunctionを使って最初にどうやってTuple2<String, Long>のストリームをStringに変換したかに注意してください。これをした理由は平文の文字列をKafkaに書き込むのが楽だからです。そして、Kafkaシンクを作成します。ホスト名とポートをセットアップに適用する必要があるかもしれません。"wiki-result" は、プログラムを実行する前に、次に生成するつもりのKafkaストリームの名前です。クラスタ上で実行するためにjarファイルが必要なため、Mavenを使ってプロジェクトをビルドします:
$ mvn clean package結果のjar ファイルは target サブフォルダ内にあるでしょう: target/wiki-edits-0.1.jar。後でこれを使うつもりです。
これで、Flinkクラスタを起動し、その上でKafkaに書き込むプログラムを実行する準備ができました。Flinkをインストールした場所に行き、ローカルクラスタを開始します:
$ cd my/flink/directory
$ bin/start-local.shプログラムが書き込めるように、Kafkaトピックを生成する必要もあります:
$ cd my/kafka/directory
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --topic wiki-resultsこれで、ローカルFlinkクラスタ上でjarファイルを実行する準備が整いました:
$ cd my/flink/directory
$ bin/flink run -c wikiedits.WikipediaAnalysis path/to/wikiedits-0.1.jar全てが計画に沿って動いた場合は、そのコマンドの出力は以下に似ていなければなりません:
03/08/2016 15:09:27 Job execution switched to status RUNNING.
03/08/2016 15:09:27 Source: Custom Source(1/1) switched to SCHEDULED
03/08/2016 15:09:27 Source: Custom Source(1/1) switched to DEPLOYING
03/08/2016 15:09:27 TriggerWindow(TumblingProcessingTimeWindows(5000), FoldingStateDescriptor{name=window-contents, defaultValue=(,0), serializer=null}, ProcessingTimeTrigger(), WindowedStream.fold(WindowedStream.java:207)) -> Map -> Sink: Unnamed(1/1) switched to SCHEDULED
03/08/2016 15:09:27 TriggerWindow(TumblingProcessingTimeWindows(5000), FoldingStateDescriptor{name=window-contents, defaultValue=(,0), serializer=null}, ProcessingTimeTrigger(), WindowedStream.fold(WindowedStream.java:207)) -> Map -> Sink: Unnamed(1/1) switched to DEPLOYING
03/08/2016 15:09:27 TriggerWindow(TumblingProcessingTimeWindows(5000), FoldingStateDescriptor{name=window-contents, defaultValue=(,0), serializer=null}, ProcessingTimeTrigger(), WindowedStream.fold(WindowedStream.java:207)) -> Map -> Sink: Unnamed(1/1) switched to RUNNING
03/08/2016 15:09:27 Source: Custom Source(1/1) switched to RUNNING
個々のオペレータがどのように開始するかを見ることができます。パフォーマンス上の理由でウィンドウの後のオペレーションが1つのオペレーションに折りたたまれるため、2つしかありません。Flinkでは、これをchainingと呼びます。
Kafkaコンソール コンシューマを使ってKafkaトピックを調査することで、プログラムの出力を調べることができます。
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wiki-resulthttp://localhost:8081 で動作している筈のFlinkダッシュボードを調べることもできます。以下のようにしてクラスタのリソースと実行中のジョブの概要を取得します:
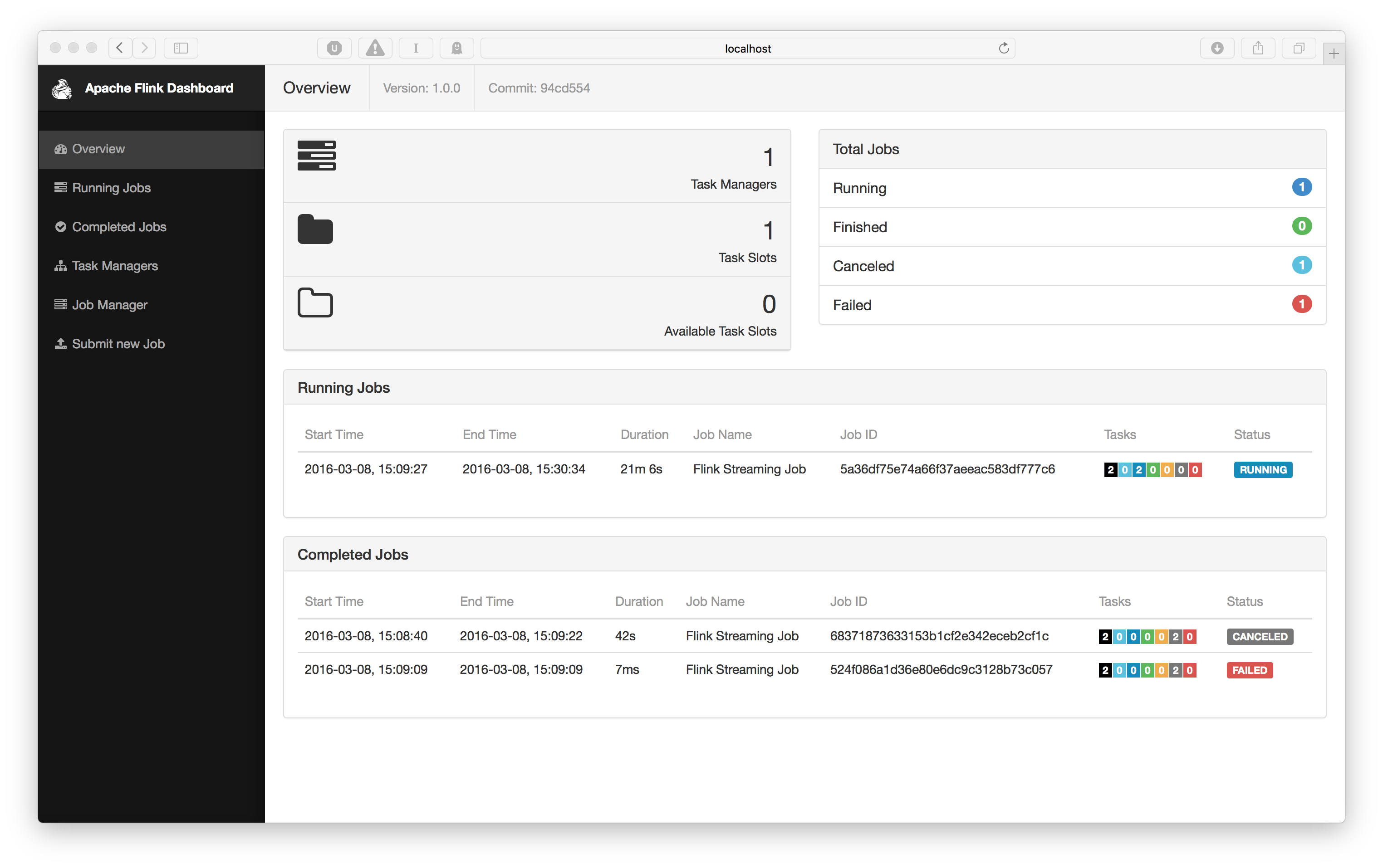
実行中のジョブをクリックすると、例えば処理された要素の数を見るような、個々のオペレーションを調査することができるビューを得るでしょう。

これでFlinkのちょっとしたツアーを終わります。何か質問があれば、気軽にメーリング リストで質問してください。