Gearpumpの内部
Actor 構造ですか?
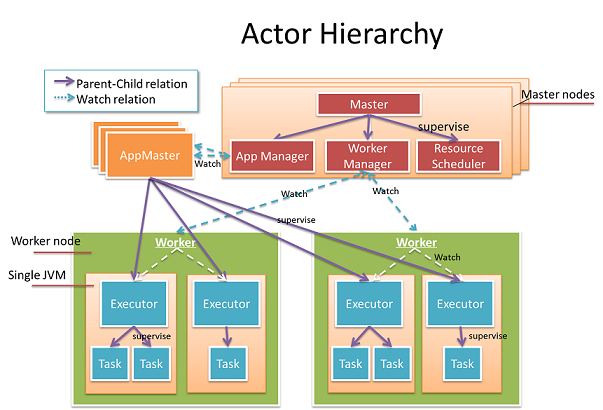
図内の全てはActorです; それらは二つのカテゴリに分類されます。クラスタActorとアプリケーションActorです。
クラスター Actor
ワーカー: 物理的なワーカーマシーンにマップします。リソースの管理に責任があり、マシーン上のマトリックスを報告します。
マスター: クラスタの心臓部; ワーカー、リソースおよびアプリケーションを管理します。主要な機能は3つの子Actor、App Manager, Worker Manager および Resource Scheduler に移譲されます。
Application Actors;
AppMaster: ワーカーへのタスクのスケジュールとアプリケーションの状態の管理に責任を持ちます。異なるアプリケーションは異なる AppMaster インスタンスを持ち、隔離されています。
Executor: AppMaster の子で、JVMプロセスを表します。その仕事はタスクのライフサイクルを管理することで、障害時にタスクを回復します。
Task: Executorの子で、実際のjobを行います。各タスクのactorはグローバルなユニークアドレスを持ちます。1つのタスクのactorは他の全てのタスクactorにデータを送信することができます。これにより、計算DAGがどうやって分散されるかについて非常に柔軟性を持ちます。
グラフ内の全てのactorはactorのスーパービジョンによって縒り合され、アクターの監視と各エラーはスーパーバイザーによって適切に処理されます。マスター内では、リスクのあるジョブは隔離され、子actorに以上されます。つまりより堅牢です。. アプリケーション内では、細かく実施できタスクの障害時には高速な回復が行えるように特別な中間レイヤ"Executor"が生成されます。 マスターは障害を処理するためにppMaster と worker のライフサイクルを監視しますが、 worker と AppMaster のライフサイクルは スーパービジョンによってマスターActor に制限されません。つまり、マスターノードは独立して失敗することがありえます。Several Master Actors form an Akka cluster, the Master state is exchanged using the Gossip protocol in a conflict-free consistent way so that there is no single point of failure. この構造の設計を使って、高可用性を達成することができます。
アプリケーションClock と グローバルClock サービス
グローバル clockサービスはシステム内で待っている全てのメッセージの最小のタイムスタンプを追跡するでしょう。各タスクは独自の最小クロックをグローバルclockサービスに更新します; タスクの最小クロックは以下を最小にするように設計されます:
- inbox内の全ての待っているメッセージの最小のタイムスタンプ。
- ackされていない外への全てのメッセージの最小タイムスタンプ。メッセージが喪失された場合は、最小クロックは進まないでしょう。
- 全てのタスクの状態の最小クロック。多くの入力メッセージによって状態が集約された場合は、クロックの値は一番古いメッセージのタイムスタンプによって決定されます。状態クロックはpersistentストレージへのスナップショットの実施、あるいは古いメッセージの影響の消失によって進むでしょう。

グローバルクロック サービスは全てのタスクの最小クロックを効果的に維持し、最小クロックのグローバルビューを維持するでしょう。グローバル最小クロック値は単調増加します; つまり、このクロック値より前の全てのソースメッセージは処理されます。メッセージの喪失あるいはタスクのクラッシュがあった場合、グローバル最小クロックは停止するでしょう。
メッセージのパスのパフォーマンスをどうやって最適化しますか?
ストリーミングアプリケーションについては、メッセージのパスのパフォーマンスは特に重要です。例えば、1つのストリーミングプラットフォームはミリ秒レベルのレイテンシで秒間あたり数百万のメッセージを処理する必要があるかも知れません。高スループットと低レイテンシを達成するのは簡単ではありません。多くの試行があります:
最初の試行: 小さなメッセージに対してネットワークは効果的ではありません
ストリーミングにといて、一般的なメッセージのサイズはとても小さく、浮遊carのGPSデータのように、通常メッセージあたり100バイト以下です。しかし、小さなメッセージを転する場合、ネットワークの効率はとても悪いです。以下の図で分かるように、メッセージのサイズが50バイトの場合、それは帯域幅の20%しか使用することができません。どうやってスループットを改善するか?

次の試行: メッセージのオーバーヘッドがあまりにも大きい
二つのactor間で送信される各メッセージについて、senderとreceiverのactorパスを含みます。有線上で送信する場合、このActorPathのオーバーヘッドは些細なものではありません。例えば、以下のactorパスは200バイト以上必要とします。
akka.tcp://system1@192.168.1.53:51582/remote/akka.tcp/2120193a-e10b-474e-bccb-8ebc4b3a0247@192.168.1.53:48948/remote/akka.tcp/system2@192.168.1.54:43676/user/master/Worker1/app_0_executor_0/group_1_task_0#-768886794これをどうやって解決するか?
Akka拡張を使って独自の Netty 転送レイヤを実装します。以下の図では、Netty クライアントは ActorPath を TaskId に変換し、Netty サーバはそれを送り返そうとするでしょう。有線上では、TaskIdだけが渡され、それは約10バイトだけであり、オーバーヘッドは最小になります。異なる Netty クライアントの Actor は隔離されます; それらはお互いをブロックしないでしょう。

パフォーマンスに関しては、効果的なバッチが本当にキーになります!複数のメッセージを1つのバッチにグループ化し、それを有線上に送信します。バッチのサイズは固定ではありません; ネットワークの状態に基づいて動的に調整されます。ネットワークが利用可能な場合、待っているメッセージは待つこと無しに即時に送信されるでしょう; そうでなければ、メッセージをバッチに配置し、後でバッチをフラッシュするためにタイマーを引き起こすでしょう。
フロー制御をどうやって行うか?
フロー制御無しでは、1つのタスクが多くのメッセージを使って他のタスクを簡単に溢れさせ、メモリ不足エラーを起こす事がありえます。ソースとターゲットがお互いにブロックしないように同時に実行することができるように、一般的なフロー制御はTCPのようなスライドウィンドウを使用するでしょう。
 図: フロー制御。各タスクは入力タスクと出力タスクで"star"接続をします。
図: フロー制御。各タスクは入力タスクと出力タスクで"star"接続をします。
問題の難しい箇所は各タスクが複数の入力タスクと出力タスクを持ち得るということです。バックプレッシャーがダウンストリームからアップストリームに適切に伝播されるように、入力と出力が調節されるようにします。フロー制御は障害と見なされる必要もあります。メッセージの喪失があった場合は回復することができるようにする必要があります。他の試行はフロー制御メッセージのオーバーヘッドが大きくなるかも知れないということです。各メッセージごとにackする場合は、システム内でackされたメッセージの量が大きくなり、ストリーミングのパフォーマンスを低下させます。採用されたやり方は明示的にAckRequestメッセージを使うことです。目的のタスクはそれらがAckRequestメッセージを受け取る場合のみackを返すでしょう。そしてソースはそれが必要と思う場合にのみAckRequestを送信するでしょう。このやり方で、オーバーヘッドを大きく減らすことができます。
メッセージの喪失をどうやって検知するか?
例えば、web adについては、各クリックについて料金を請求するかもしれません。私たちはカウントを失敗したくありません。ストリーミングプラットフォームは効果的にどのメッセージが喪失されたかを追跡し、そしてできるだけ早く回復する必要があります。
 図: メッセージ喪失の検知
図: メッセージ喪失の検知
フロー制御メッセージのAckRequestを使用し、メッセージの喪失を検知するためにAckを使います。target タスクは最後のAckRequestから受信したメッセージの数をカウントし、sourceタスクにカウントをackするでしょう。source タスクはカウントをチェックしメッセージの喪失を見つけるでしょう。これは説明のためのものであり、実際の場合にはもっと難しいです。ゾンビタスクとその場での陳腐なメッセージを処理する必要があります。
Gearpumpはどのメッセージを再生するかをどうやって知りますか?
あるアプリケーションでは、メッセージは喪失することができず、再生されなければなりません。例えば、お金の転送の間、銀行は検証コードをSMSするでしょう。メッセージが喪失されると、システムはお金の転送を継続できるように再生しなければなりません。ソースエンドメッセージ ストレージ と タイムスタンプに基づいた再生を使うと決めました。
 図: ソースエンドメッセージ ストアを使った再生
図: ソースエンドメッセージ ストアを使った再生
各メッセージは不変で、タイムスタンプでタグ付けされています。タイムスタンプはおよそ増加すると仮定します(ちょっとしたメッセージの乱雑を許可します)。
メッセージはKafkaキューのような再生可能なソースからやってくると仮定します; そうでなければ、メッセージはカスタマイズ可能なソースエンド "メッセージストア"に格納されるでしょう。ソースタスクがメッセージをダウンストリームに送信する場合、メッセージのタイムスタンプとオフセットは定期的にオフセット タイムスタンプ ストレージにもチェックポイントされます。回復の間、システムはまずオフセットタイムスタンプ ストレージから正しいタイムスタンプとオフセットを取り出し、タイムスタンプとオフセットからメッセージストアを再生するでしょう。メッセージストア内のメッセージが厳密に時間順では無い場合、タイムスタンプフィルターは古いメッセージをフィルタして取り除くでしょう。
マスター高可用性
分散ストリーミングシステムの中で、部分が失敗することがありえます。エラーの場合に、システムはすぐに応答し回復をしなければなりません。
 図: マスター高可用性
図: マスター高可用性
マスター高可用性を実装するためにAkkaクラスタリングを使います。クラスターはいくつかのマスターノードからなりますが、ワーカーノードはありません。クラスタ能力を使って、簡単にマスターノードのクラッシュの障害を検知し処理することができます。マスターの状態はTypesafe akka-data-replicationライブラリを使って全てのマスターノード上でリプリケートされます。一つのマスターノードがクラッシュした場合、他のスタンバイマスターはマスターの状態を読み込み、引き継ぐでしょう。マスターの状態は全てのアプリケーションのサブミッションデータを含みます。1つのアプリケーションが死んだ場合、マスターはアプリケーションの回復をするためにその状態を使うことができます。CRDT LwwMap は状態を表すために使われます; 分散されたノード上で衝突無しに集約することができるハッシュマップです。強力なデータの一貫性を持つために、状態の読み込みと書き込みは定員が充足されたマスターノード上で行われなければなりません。
障害をどうやって処理しますか?
Akkaの強力なactorスーパービジョンを使って、弾力のあるシステムを比較的簡単に実装することができます。Gearpumpでは、異なるアプリケーションは異なるAppMasterインスタンスを持ち、それらは全体としてそれぞれから隔離されます。各アプリケーションについては、スーパービジョンツリー AppMaster->Executor->Task があります。このスーパービジョン階層を使うことで、ゾンビプロセスの悩みから解放されることができます。例えば、もしAppMasterがダウンした場合、Akkaスーパービジョンはツリー全体がシャットダウンされることを保証します。
複数の有り得る障害シナリオ
 図: ありえる障害シナリオとエラーのスーパービジョン階層
図: ありえる障害シナリオとエラーのスーパービジョン階層
Masterがクラッシュした場合に何が起きるか?
マスターがクラッシュした場合、他のスタンバイマスターが気づくでしょう。それらはマスターの状態を回復し、制御を引き継ぎます。ワーカーとAppMasterも気付くでしょう。それらは転換が完了するまで新しいアクティブなマスターを見つけるためのプロセスを起動します。AppMasterあるいはワーカーがタイムアウトで新しいマスターを決定できない場合、それらは自殺し、自身をkillします。
ワーカーがクラッシュした場合に何が起きるか?
ワーカーがクラッシュした場合、マスターはそれに気づき、このワーカーに新しい計算をスケジュールすることを止めるでしょう。現在のワーカー上の全ての監視されているexecutorはkillされ、AppMasterは executorがクラッシュした場合に何が起きるか?のようにexecutorのクラッシュの回復としてそれを扱うことができます。
AppMasterがクラッシュした場合に何が起きるか?
AppMasterがクラッシュした場合、マスターは他の場所で新しいAppMasterインスタンスを生成するために新しいリソースをスケジュールし、AppMasterはアプリケーション内で回復を処理するでしょう。ストリーミングについては、最新の最小クロックと他の状態をディスクから回復し、マスターがexecutorを開始するようにリソースをリクエストし、回復された最小クロックを使ってタスクを再起動するでしょう。
executorがクラッシュした場合に何が起きるか?
executor がクラッシュすると、そのスーパーバイザーのAppMasterは知らせを受け、新しいexecutorを開始し、クラッシュしたexecutor上にあったタスクを実行するために、アクティブなマスターから新しいリソースを要求するでしょう。
タスクがクラッシュした場合に何が起きるか?
タスクが例外を投げると、スーパーバイザーのexecutorはタスクを再起動するでしょう。
"少なくとも一回"のメッセージの配送が有効な場合、メッセージの喪失の場合にメッセージの再送を引き起こすでしょう。最初にAppMasterは最新の最小クロックをグローバルクロックサービス(あるいはクロックサービスがクラッシュした場合はクロックストレージ)から読み込み、AppMasterはタスクの状態を新鮮にするために全てのタスクのactorを再起動し、ソースの最後のタスクは最小クロックからメッセージを再生するでしょう。
"確実に一回"のメッセージ配送はどのように動作するか?
あるアプリケーションにとって、"確実に一回"のメッセージ配送はとても重要です。例えば、リアルタイム請求システムの場合、顧客に二回請求したくはないでしょう。"確実に一回"のメッセージ配送の目的は、以下を確実にすることです: エラーが累積せず、今日のエラーは明日に累積しない。アプリケーション開発者にとって分かりやすいように、分散トランザクションを同期するためにグローバルクロックを使います。データソースからの各メッセージはユニークなタイムスタンプを持ち、タイムスタンプはメッセージボディの一部となることができ、あるいはメッセージがストリーミングシステムに投入された時にシステムクロックが付け足されると見なします。このグローバル同期クロックを使って、全てのタスクが同じタイムスタンプでチェックポイントできるように調整します。
 図: チェックポイントと確実に一回のメッセージの配送
図: チェックポイントと確実に一回のメッセージの配送
Workflow to do state checkpointing:
- 調整者はストリーミングシステムにタイムスタンプTcでチェックポイントするように依頼します。
- 各アプリケーションタスクにとって、それは二つの状態、チェックポイント状態と現在の状態を保持するでしょう。チェックポイントの状態はタイムスタンプTC以前の情報のみを含みます。現在の状態は全ての情報を含みます。
- グローバル最小クロックがTcよりも大きい場合、それはTcより古い全てのメッセージが処理されたことを意味します; チェックポイントの状態はもう変化することは無いでしょう。つまり、チェックポイントの状態を安全にストレージに維持するでしょう。
- メッセージの喪失があった場合、回復プロセスを開始するでしょう。
- 回復するためには、ストアから最新のチェックポイントの状態をロードし、それを使ってアプリケーションの状態を回復します。
- データソースはチェックポイントのタイムスタンプからメッセージを再生します。
チェックポイントの間隔はグローバルクロックサービスによって動的に決定されます。各データソースは入力メッセージの最大のタイムスタンプを追跡するでしょう。最小のクロックの更新を受信する時に、データソースはグローバルクロックサービスに時間の差分を報告するでしょう。最大の時間の差分はアプリケーションの状態の時間間隔の上限です。チェックポイントの間隔は最大の時間差分よりも大きいです:

 図: チェックポイントの間隔の決め方
図: チェックポイントの間隔の決め方
チェックポイントの間隔がグローバルクロックサービスによってタスクに通知された後で、各タスクはグローバルの同期無しに次のチェックポイントのタイムスタンプを自発的に計算するでしょう。

各タスクについて、それは二つの状態、チェックポイント状態と現在の状態、を持ちます。状態を更新するコードを以下のリストに示します。
TaskState(stateStore, initialTimeStamp):
currentState = stateStore.load(initialTimeStamp)
checkpointState = currentState.clone
checkpointTimestamp = nextCheckpointTimeStamp(initialTimeStamp)
onMessage(msg):
if (msg.timestamp < checkpointTimestamp):
checkpointState.updateMessage(msg)
currentState.updateMessage(msg)
maxClock = max(maxClock, msg.timeStamp)
onMinClock(minClock):
if (minClock > checkpointTimestamp):
stateStore.persist(checkpointState)
checkpointTimeStamp = nextCheckpointTimeStamp(maxClock)
checkpointState = currentState.clone
onNewCheckpointInterval(newStep):
step = newStep
nextCheckpointTimeStamp(timestamp):
checkpointTimestamp = (1 + timestamp/step) * stepリスト1: タスク トランザクション 状態実装
動的なグラフとは何か、またどうやって動作するか?
DAG は動的に修正することができます。動的にサブグラフの追加、削除そして置き換えをできるようにしたいです。
 図: 動的グラフ、追加、置き換え、および削除
図: 動的グラフ、追加、置き換え、および削除
少なくとも一回のメッセージ配送とKafka
Kafkaソースの例のプロジェクトとチュートリアルは以下で見つけることができます: -Kafka コネクタの例のプロジェクト - kafkaソースとの接続
このドキュメントの中で、少なくとも一回のメッセージの配送がどう動くかについて話そうと思います。
説明のためにソースツリーの例のWordCountを使うつもりです。
KafkaのWordCountのDAGはどのように見えるか:
3つのプロセッサを含みます:

- KafkaStreamProducer(あるいは KafkaSource) はKafkaキューからメッセージを読むでしょう。
- Split は行を単語に分割するでしょう。
- Sum は各単語について数を数えるために集計するでしょう。
Kafkaからデータを読む方法
KafkaSourceを使います。導入についてはKafka ソースとの接続 をチェックしてください。
KafkaSourceのためにstartTimestampを設定したことに注意してください。これはKafkaSourceがタイムスタンプがstartTimestampに近いメッセージから始まるKafkaキューから読み込むでしょう。
タスクがクラッシュあるいはメッセージが喪失した場合に何が起きるか?
メッセージの喪失がある場合、AppMasterはグローバル最小タイムスタンプがもう変更されないようにまずグローバルクロックサービスを停止します。そして、Kafkaソースタスクを再起動するでしょう。 再起動時に、Kafkaソースは再生を始めるでしょう。まずグロバル最小タイムスタンプをAppMasterから読み込み、メッセージをそのタイムスタンプから読み込み始めるでしょう。
KafkaSourceが開始タイムスタンプからメッセージを読み込むためにどのような手段を使うか?知っての通り、Kafkaキューはタイムスタンプの情報を公開しません。
Kafka キューは各パーティションに関してオフセットの情報のみを公開します。KafkaSourceがすることは、アプリケーションタイムスタンプからKafkaオフセットへマップし、KafkaメッセージをKafkaオフセットから再生できるように、Kafkaオフセットからアプリケーションタイムスタンプへの独自のマッピングを維持することです。
アプリケーションタイムスタンプとKafkaオフセットとの間のマッピングは、分散ファイルシステム内あるいはKafkaトピックとして格納されます。